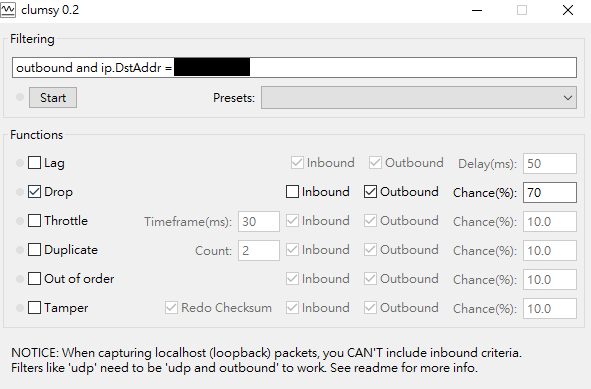
I’m curious how cache-control directives affect caching, so I made a small experiment to see the interaction between browser, reverse proxy and server.
First of all, I introduced 6 APIs that respond different cache-control value in response header and current time only.
Reponse Cache-Control
[GET]/cache/get-public
public,max-age=120
[GET]/cache/get-private
private,max-age=120
[GET]/cache/get-unset
max-age=120
[DELETE]/cache/delete-public
public,max-age=120
[DELETE]/cache/delete-private
private,max-age=120
[DELETE]/cache/delete-unset
max-age=120
Then I created a simple web page for test
By clicking the buttons, APIs were called and showed the response data on page. Meanwhile, I monitored the developer tool and record the results.
The results of browsers reaction. (on safari, chrome and edge)
(v) : cached
(X) : none-cached
Http Method \ Cache Directive
Public
Private
Unset
GET
V
V
V
DELETE
X
X
X
The results of reverse proxy reaction.
Http Method \ Cache Directive
Public
Private
Unset
GET
V
X
X
DELETE
X
X
X
According to the results, we know that the browsers would not break the rule of cacheable, and reverse proxy may not store the response when you don’t set public/private directives.
Recently I found that the HttpClient doesn’t change cookie value per request, and it will cache the value for 2 minutes after the first request which have set the cookie value sent.
var request = new HttpRequestMessage(HttpMethod.Post, "/the/api"); // set request content request.Content = new StringContent("mydata", Encoding.UTF8, "application/json"); // set cookie here request.Headers.Add("Cookie", $"user.token={token}");
var response = await _httpClient.SendAsync(request); response.EnsureSuccessStatusCode(); var res = await response.Content.ReadAsStringAsync();
... } }
Register MyHttpClient to the Denpency Injection provider.
1 2 3 4 5
services.AddHttpClient<IMyHttpClient, MyHttpClient>(config => { config.BaseAddress = new Uri("https://my.server.com"); });
When I use CallAPI() of MyHttpClient, I found the cookie doesn’t change value per request, and it will cache value for 2 minutes.
Why
HttpClient is just a container of HttpClientHandler. If you trace the source code on Github you will see the code
public HttpClient CreateClient(string name) { if (name == null) { thrownew ArgumentNullException(nameof(name)); }
var handler = CreateHandler(name); var client = new HttpClient(handler, disposeHandler: false);
var options = _optionsMonitor.Get(name); for (var i = 0; i < options.HttpClientActions.Count; i++) { options.HttpClientActions[i](client); }
return client; }
public HttpMessageHandler CreateHandler(string name) { if (name == null) { thrownew ArgumentNullException(nameof(name)); }
var entry = _activeHandlers.GetOrAdd(name, _entryFactory).Value;
StartHandlerEntryTimer(entry);
return entry.Handler; }
When you are asking for HttpClient, HttpClientFactory will generate a HttpClient instance everytime and try to get HttpMessageHandler from the pool. Why HttpClientFactory maintains HttpMessageHandler pool for us? Because creating TCP connections are extremely expensive, so we should reuse it as we can as possible.
So multiple HttpClients will possibly use same HttpMessageHandler. HttpMessageHandler has Property named CookieContainer. It will store cookie value when you first time to set the value. So it will cause different requests using same cookie value until HttpMessageHandler expired.
Solution
There is a way to stop HttpMessageHandler using CookieContainer.
1 2 3 4 5 6 7 8 9
services.AddHttpClient<IPortalShellClient, PortalShellHttpClient>(config => { config.BaseAddress = new Uri(clientConfig.PortalSiteEndpoint); }) .ConfigurePrimaryHttpMessageHandler(() => { //Tell HttpMessageHandler to stop using CookieContainer returnnew HttpClientHandler { UseCookies = false }; });
每當我們交付功能給客戶,面對客戶的不滿意時,常常歸因於需求描述的失準,開發團隊內會互相抱怨、指責,開發者埋怨開需求的人規格亂寫,開需求的人埋怨開發者搞不清楚也不問,導致開發出來的系統與最終想解決的問題有一大段落差,所以團隊可能會開始找更厲害的 PO 或 PM,開始要求規格書的格式,試圖用鉅細彌遺厚厚一本的規格書來彌補與真實之間的落差。
最前面提到在不同情境下,User 可能代表的意義完全不同,當我們在討論過程中可能會脫口而出前台的消費者、平台的廠商、後台的管理者…等等,而當這些用語的不同時,其實也幫助了我們發現了新的情境,針對這些新出現的情境建立對應的模型是需要的,對比於前面只用 使用者(User)來描述,後者更精準也更貼近真實,這也可以避免開發者寫出近乎於上帝類別的 User 來。
publicvoidUpdate(MemberDto member) { var memberEntity = MemberRepository.Get(member.Id); if(memberEntity == null) thrownew NullReferenceException("Member not found.");
if(string.IsNullOrEmpty(member.Name)) thrownew ArgumentNullException(nameof(member.Name)); if(DateTime.TryParse(member.Birthday, outvar birthday) == false) thrownew ArgumentException(nameof(member.Birthday)); //bla bla bla ....
if(string.IsNullOrEmpty(member.Password)) thrownew ArgumentNullException(nameof(member.Password)); // Set Entity ...
memberEntity.Password = member.Password;
MemberRepository.Update(memberEntity); }
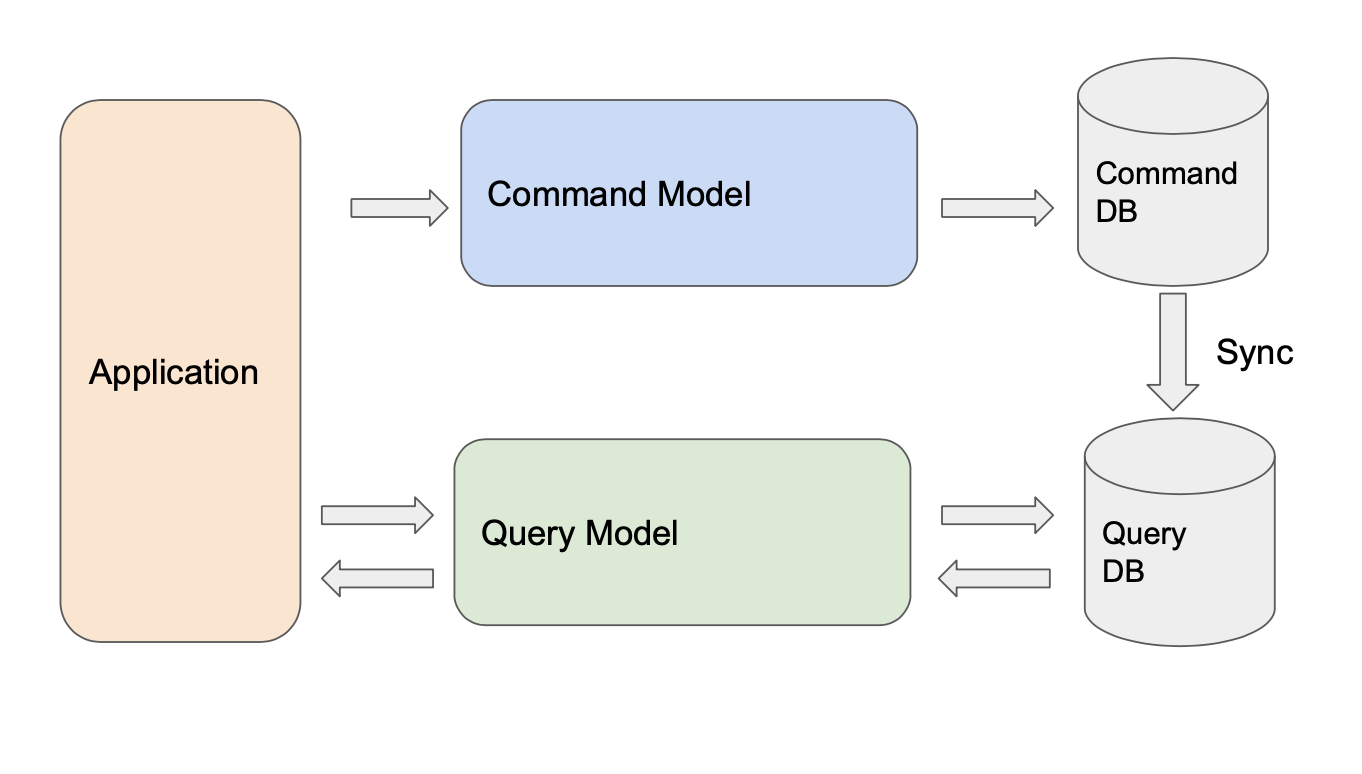
這個 API 可能包含了對 Member 資料的各種邏輯驗證,而呼叫這個 API 的你可能只是為了完成密碼變更而已,這份 Code 硬要說沒什麼大問題,但也體現了從 CRUD 角度設計出的 API 可能隨著商業邏輯的日益複雜,複雜度可能會成長到非常可怕的地步,而這也是 CQRS 中想避免的事情。
Command 會這樣做
1 2 3 4 5 6 7 8 9 10 11
publicvoidHandle(ResetPasswordCommand command) { var member = MemberRepository.Get(command.Id); if(memberEntity == null) thrownew NullReferenceException("Member not found.");
最近接到一個任務,需要協助團隊重現幾個 DB 連線時的錯誤,例如: connection pool 超過上限爆掉、connection timeout 等等,而其中一個錯誤 Pre-Login handshack 最難重現
1 2
System.Data.SqlClient.SqlException (0x80131904): Connection Timeout Expired. The timeout period elapsed while attempting to consume the pre-login handshake acknowledgement. This could be because the pre-login handshake failed or the server was unable to respond back in time. The duration spent while attempting to connect to this server was - [Pre-Login] initialization=2846; handshake=6765;
這個錯誤推測是在與 SQL Server 連線時 three-way handshake 沒有收到回應導致的失敗,可能屬於網路不穩掉封包問題導致,但問題怎麼證明?
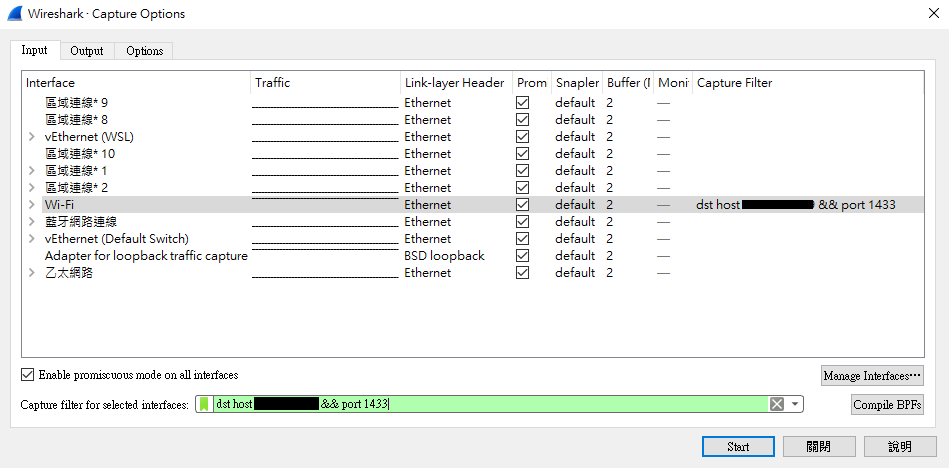
Wireshark
首先得先確認與 SQL Server 連線時到底傳了哪些封包出去,可以透過 wireshark 側錄封包的功能來達成