學生時期學資料結構跟演算法時,每次看到厚厚的課本加上一堆用C語言寫的範例,雖然都有修過,但說真的不知道它可以拿來做什麼? 直到出了社會開始寫一些專案要調教效能時,才發現原來以前學的是這麼厲害的東西阿。
開始前想先推薦一下這本書【**演算法圖鑑:26種演算法 + 7種資料結構,人工智慧、數據分析、邏輯思考的原理和應用全圖解**】,作者用簡單的圖解方式帶領讀者瞭解艱澀的資料結構與演算法的歷程,雖然要實際應用在專案中還需要一些內化,但已經比我以前的課本好多了(拭淚),對這方面有興趣的非常推薦買這本書來看看

圖片出處: http://www.books.com.tw/products/0010771263
案例
公司有派送Coupon券的需求,而條件是該券不能與過往中的任何一張重複,所以在產生Coupon券代碼後,最好跟以前的做一下比對來確保沒有發生重複的情形,而Coupon券為英數字12個字元格式,區分大小寫,比對方法想過以下幾種方式
1. 寫入時,用SQL語法的方式要求DB先搜尋確定沒有再寫
- 優點 : 寫法簡單
- 缺點 : 耗掉DB效能,當要寫入的筆數一多時,DB會出現效能瓶頸
2. 將全部的Coupon券撈出來後,進行比對,確定沒有再進行寫入
- 優點 : 因為是將資料撈出DB再從Application端做比對,所以對DB負擔較小
- 缺點 : 進行字串比對時該如何有效率執行是個問題,尤其是字串比對,如果處理方式不佳,也一樣會在Application端產生效能瓶頸
這邊我採取方式2並搭配雜湊表來解決,而為何要用雜湊表以下慢慢說明
產生Coupon券的程式如下
1 | /// <summary> |
執行方式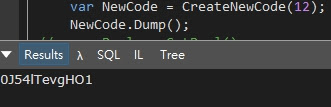
List
如果你是寫C#的,那要比對是否有一樣的東西存在List中最快的方式就是用Any()這個方法,而我們知道List儲存方式實際是這樣
記憶體位置放置資料內容,而每個節點會記錄下一筆資料的記憶體位置在哪,所以List裡面的資料未必是一個相連的記憶體區段,但它只要知道開頭那筆資料,就可以依序將資料逐筆讀取出來。
換言之,如果要搜尋一個列表中是否有相同的資料存在,必須用線性的方式搜尋,也就是逐筆檢查,從第一筆開始每筆拿出來看看,直到比對到為止,最佳的狀況是第一筆就是你要比對的資料,最差,就是最後一筆才是你要的資料,而且搜尋的成本會隨著資料的增長而遞增。
1萬筆資料搜尋效能
1 | int 產生的資料筆數 = 10000; |
實際算出來的平均搜尋時間為 0.083978(毫秒)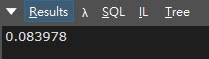
100萬筆資料搜尋效能
將搜尋母體放大100倍,也就是從100萬筆資料中隨機抽樣搜尋100次,結果為8.540132(毫秒)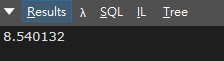
可以觀察到搜尋效率隨著資料量的增長快速遞減,而一百萬筆對於Coupon券來說其實不多,如果你的會員數有一萬人,每個人發到第100張時,總共發出去的數量就達到這個等級了 ,相信很多店商平台所產出的Coupon數遠遠大於這個量。
雜湊表
雜湊表與List的最大差異是它非線性搜尋,它將所有要放入的資料先進行雜湊的方式算出一個值後,依據算出來的值放到對應的記憶體位置去,搜尋時也是先將要搜尋的值進行雜湊運算,算出對應位置,直接取出該記憶體的資料進行比對

特點是它非線性搜尋,也就是說它不需要抓到第一筆資料後,依序依據指標,往下找下一筆資料,即便不是還是要每筆遍尋才能知道結果,雜湊表的好處就在於,你要搜尋時,就已經知道該去哪找了。
而可能會有一個問題,那如果經過運算後,兩筆資料要儲存的地方一樣呢?這時候就是發生所謂的碰撞,一張好的雜湊表理論上要盡量避免碰撞發生,但現實中難以避免,所以進階的用法就是將相同位置內再放入List來存入更多筆資料。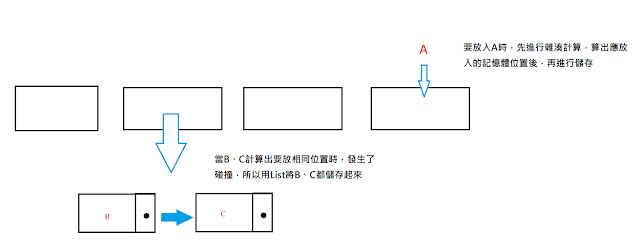
這邊可能會有一個疑問是,那跟我一開始用List有什麼差別 ?
如果我們相信資料是平均分佈,那雜湊結果理論上也會平均分佈,但就如前面提的,現實中實在難以避免碰撞的發生,所以即便真的發生碰撞,我們也能確定List中的資料絕對不會有很多筆,多到導致效能瓶頸的發生。所以雜湊表的陣列該開出幾格來就是需要經過考量的,如果你有數百萬筆的資料,只開出100格,那最平均的結果就是每一格裡面會有1萬筆的資料,這顯然不理想。
1萬筆資料搜尋效能
1 | int 產生的資料筆數 = 10000; |
實際算出來的平均搜尋時間為 0.004124(毫秒)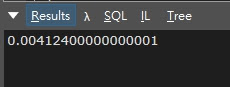
100萬筆資料搜尋效能
一樣將數字放大到100萬筆,實際算出來的平均搜尋時間為 0.033612(毫秒),可以發現即便搜尋筆數擴張了100倍,效率並沒有完全等比遞減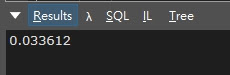
當然各種資料型態跟搜尋狀況不同,可能適用的資料結構與演算法也會略有不同要取捨,雜湊法也並非沒有缺點,例如在製作表時比較耗時,所以適合用在資料變動不大的情境,先將表做起來後放到快取去更新維護都是一些優化的方法,以上提供給大家參考。